#StandWithUkraine - Stop the Russian invasion
Join us and donate. Since 2022 we have contributed over $5,000 in book royalties to Save Life in Ukraine & Ukraine Humanitarian Appeal & The HALO Trust, and we will continue to give!
Extract Tables from PDFs with Tabula
It sometimes happens that the dataset you are interested in is only available as a PDF document. Don’t despair, you can likely use Tabula to extract tables and save them as CSV files. Keep in mind that PDFs generally come in two flavors: text-based and image-based. If you can use cursor to select and copy-paste text in your PDF, then it’s text-based, which is great because you can process it with Tabula. But if you cannot select and copy-paste items inside a PDF, then it’s image-based, meaning it was probably created as a scanned version of the original document. You need to use optical character recognition (OCR) software, such as Adobe Acrobat Pro or another OCR tool, to convert an image-based PDF into a text-based PDF. Furthermore, Tabula can only extract data from tables, not charts or other types of visualizations.
Tabula is a free tool that runs on Java in your browser, and is available for Mac, Windows, and Linux computers. It runs on your local machine and does not send your data to the cloud, so you can also use it for sensitive documents.
To get started, download the newest version of Tabula. You can use download buttons on the left-hand side, or scroll down to the Download & Install Tabula section to download a copy for your platform. Unlike most other programs, Tabula does not require installation. Just unzip the downloaded archive, and double-click the icon.
On a Mac, you may see this warning when launching Tabula for the first time: “Tabula is an app downloaded from the internet. Are you sure you want to open it?” If so, click Open, as shown in Figure 4.10.
Figure 4.10: Mac users may need to confirm that they wish to open Tabula the first time.
When you start up Tabula, it opens your default browser as a localhost with a URL similar to http://127.0.0.1/, with or without an additional port number such as with :8080, as shown in Figure 4.11. Tabula runs on your local computer, not the internet. If your default browser (such as Safari or Edge) does not play nicely with Tabula, you can copy-and-paste the URL into a different browser (such as Firefox or Chrome).
Figure 4.11: Tabula welcome page.
Now let’s upload a sample text-based PDF and detect any tables we wish to extract. In the beginning of the Covid-19 pandemic, the Department of Public Health in Connecticut issued data on cases and deaths only in PDF document format. For this demonstration, you can use our sample text-based PDF from May 31, 2020, or provide your own.
Select the PDF you want to extract data from by clicking the blue Browse… button.
Click Import. Tabula will begin analyzing the file.
As soon as Tabula finishes loading the PDF, you will see a PDF viewer with individual pages. The interface is fairly clean, with only four buttons in the header.
Click the Autodetect Tables button to let Tabula look for relevant data. The tool highlights each table it detects in red, as shown in Figure 4.12.
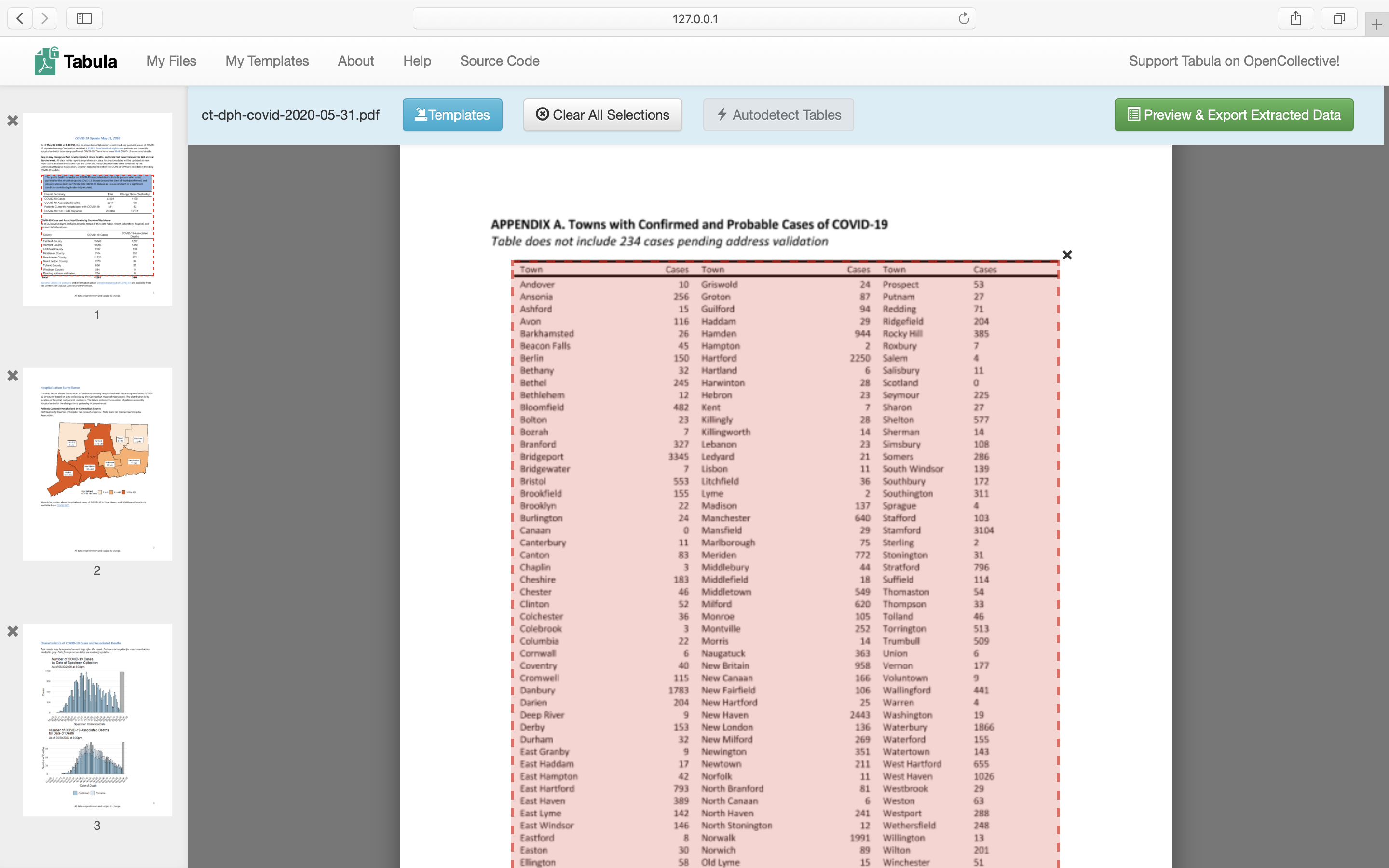
Figure 4.12: Click Autodetect Tables, which Tabula will highlight in red.
Now let’s manually adjust our selected tables and export the data.
Click Preview & Export Extracted Data green button to see how Tabula thinks the data should be exported.
If the preview tables don’t contain the data you want, try switching between Stream and Lattice extraction methods in the left-hand-side bar.
If the tables still don’t look right, or you with to remove some tables that Tabula auto-detected, hit Revise selection button. That will bring you back to the PDF viewer.
Now you can Clear All Selections and manually select tables of interest. Use drag-and-drop movements to select tables of interest (or parts of tables).
If you want to “copy” selection to some or all pages, you can use Repeat this Selection dropdown, which appears in the lower-right corner of your selections, to propagate changes. This is extremely useful if your PDF consists of many similarly-formatted pages.
Once you are happy with the result, you can export it. If you have only one table, we recommend using CSV as export format. If you have more than one table, consider switching export format in the drop-down menu to zip of CSVs.This way each table will be saved as an individual file, rather than all tables inside one CSV file.
After you have exported your data to your computer, navigate to the file and open it with a spreadsheet tool to analyze and visualize.
Now that you have extracted a table from a PDF document, the results may be messy. In the next section, we will clean up messy datasets with a very powerful tool called OpenRefine.