#StandWithUkraine - Stop the Russian invasion
Join us and donate. Since 2022 we have contributed over $5,000 in book royalties to Save Life in Ukraine & Ukraine Humanitarian Appeal & The HALO Trust, and we will continue to give!
B Publishing with Bookdown
We built this book with free-to-use, open-source tools, primarily Bookdown, GitHub, and Zotero. This chapter explains why and how we combined these tools and developed our publishing workflow, so that others can build their own books and share their knowledge about how to improve the process.
Why not just write the book in a conventional word processor? We desired an efficient workflow to co-author one manuscript that could continuously generate multiple book products for different purposes, as shown in Figure B.1.
- HMTL web edition for the open-access book, with embedded iframes for interactive charts and maps
- PDF print edition with static images and book-style layout
- Microsoft Word edition with static images for editors who prefer to provide feedback this way
- Markdown file of the full-length book with pathnames to static images for easy conversion into the publisher’s platform
A conventional word processor could not continuously generate all of these products, which likely would have resulted in creating entirely separate files and code for different editions. But with our unified Bookdown workflow, all of our writing is done in one manuscript. Whenever we make edits, we push a couple of buttons to publish our updated book products in the HTML, PDF, MS Word, and Markdown formats.
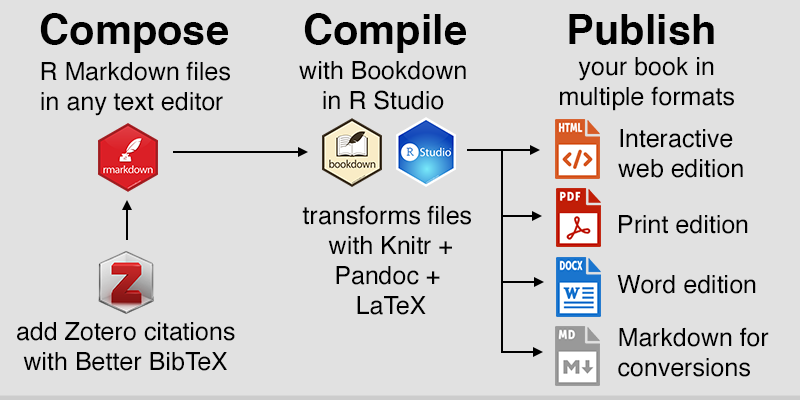
Figure B.1: Simplified workflow to compose, compile, and publish in multiple formats with Bookdown. Images from Daniel Hendricks, RStudio, and Zotero.
Here’s a three-minute video that demonstrates the process:
Figure B.2: Short video of our Bookdown workflow. View on YouTube.
Bookdown Overview: Why and How?
We based our solution around Bookdown, an open-source package for the R code project created by Yihui Xie at RStudio. Although many people use R for statistical analysis, the free RStudio desktop application also supports several innovative publishing solutions. Here’s an overview of our workflow:
- We set up the Bookdown files and composed the manuscript in R Markdown, the R-flavored version of the easy-to-write Markdown syntax. Each chapter consisted of one .Rmd file, with links to static images and interactive visualizations.
- We uploaded our files to a free GitHub repository, which allows multiple authors to work simultaneously on different chapters of the book and “push” revisions (called commits) to a shared online repository, where authors can view each other’s edits. Alternatively, you could simultaneously write and comment on the same chapter in Google Documents, and use the Docs to Markdown add-on to convert one-time into Markdown format, which is similar to R Markdown.
- We organized our sources using the free Zotero bibliography manager by the Roy Rosenzweig Center for History and New Media at George Mason University. Also, we installed the free Better BibTeX extension by Emiliano Heynes to create Zotero citation keys that work smoothly with Bookdown.
- After each day’s writing, we used Bookdown to automatically “knit” and compile the book products. Behind the scenes, Bookdown builds the editions using the PanDoc universal document converter and the LaTeX document preparation software, without requiring you to learn these complex formats.
- Under our open-access agreement with the publisher, we made our book public as we wrote it to develop our audience and address reader feedback. With each day’s revisions, we rebuilt the book and published all of the editions to our public GitHub repository, and used its free GitHub Pages feature to host the open-access HTML web edition. (Alternatively, you can choose to keep your GitHub repo private.)
- We hosted our open-access web edition on GitHub using a custom domain name (https://HandsOnDataViz.org), which we purchased and set up through Reclaim Hosting.
- As we worked on the book manuscript, our developmental editor downloaded the PDF edition from our public GitHub repo to mark up with feedback. (Alternatively, some editors prefer to insert track-changes comments in the MS Word edition.)
- When we were ready to submit the final manuscript, we used Bookdown to create one full-length Markdown file of the entire book, which was compatible with the publisher’s Atlas production platform. However, this was a one-time file conversion, and edits we make to our Bookdown workflow will not appear in the publisher’s platform, unless they request a new file and convert it.
Screenshots of two variations of the basic workflow appear in Figure B.3 and Figure B.4. The first displays how to compose the book using the R Studio built-in editor, and the second shows a very similar process using the Atom text editor, which we prefer. Learn more about GitHub Desktop and Atom text editor in Chapter 10.
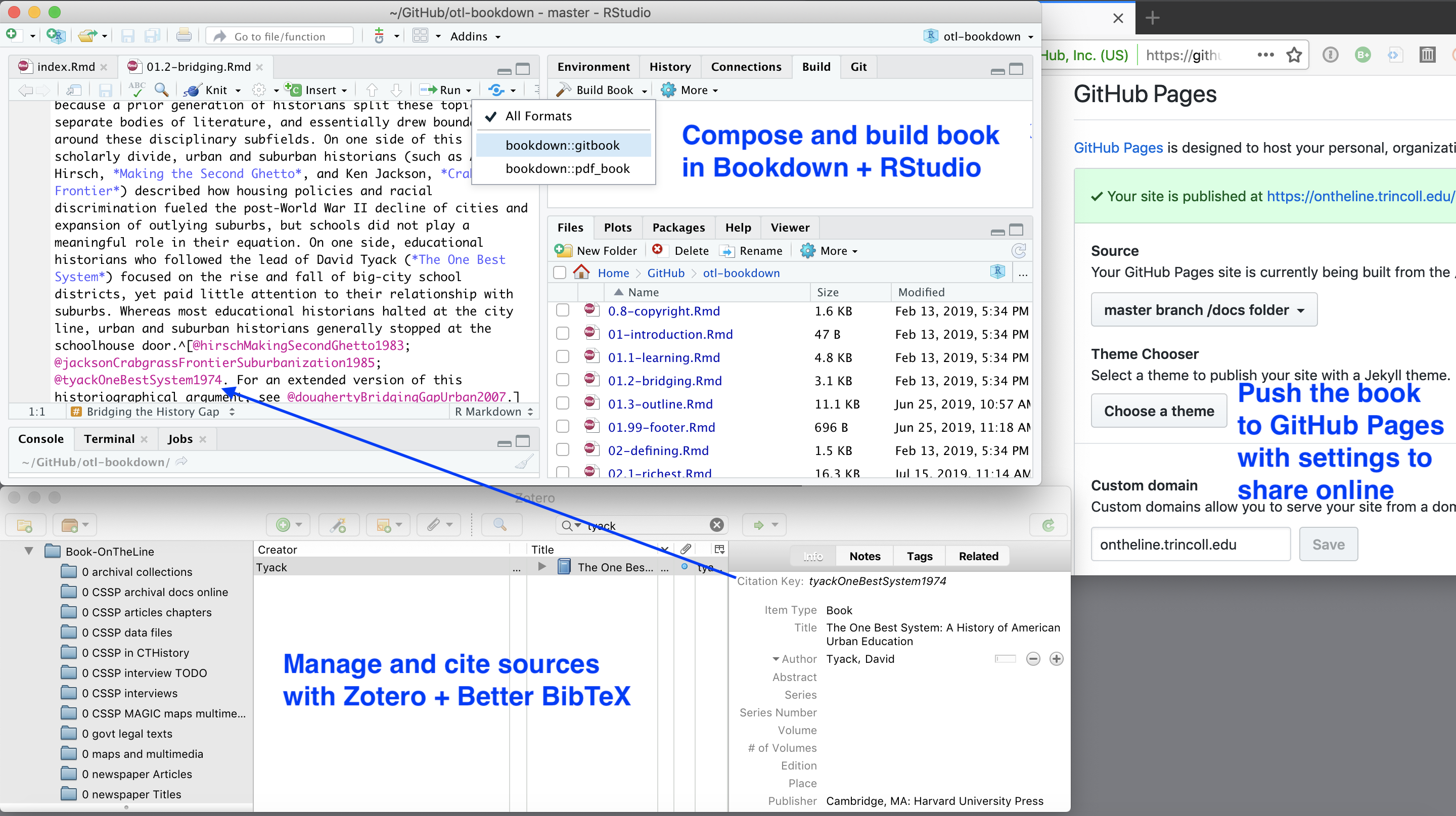
Figure B.3: Workflow on a Mac desktop: Compose the text in RStudio and build books with Bookdown (top left), manage sources and insert citation keys with Zotero + BetterBibTex (bottom left), push book products to your GitHub repository to host online (right).
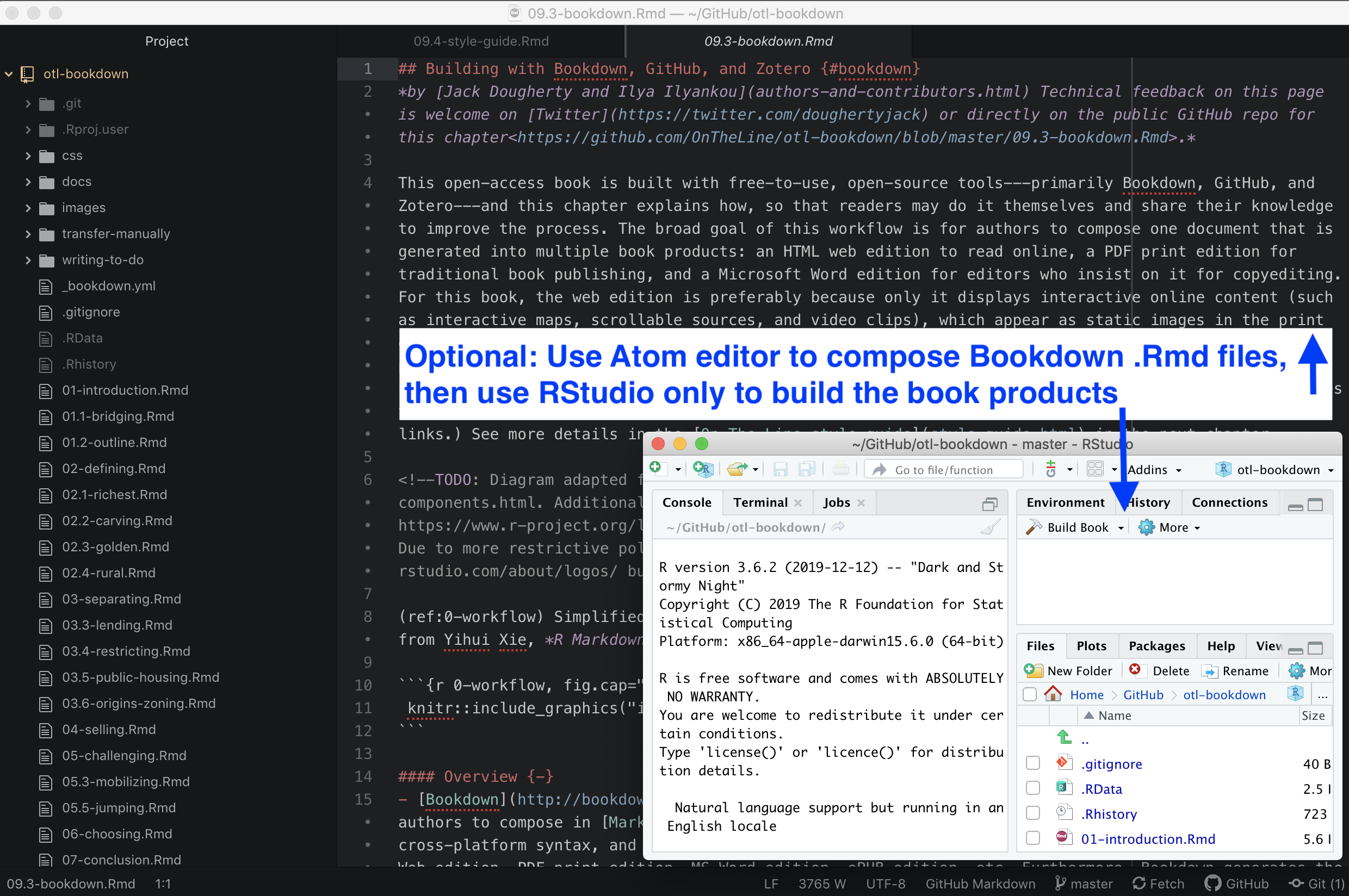
Figure B.4: Variation on the workflow above: Compose the text in your preferred editor (such as Atom), and use RStudio only to build the book products.
Our Bookdown workflow met our goal to efficiently and continuously produce multiple book products. But it may not be ideal for everyone, especially novice computer users. Installation and setup requires several steps, as described in the following sections:
- Install and Set Up Bookdown
- File Structure and Headers
- Style Guide for Hands-On Data Visualization
- Images and R Code-chunk Formatting
- Tables in Markdown Format
- Zotero and Better BibTeX for Notes and Biblio
Before leaping into Bookdown or any related tool, see also this section on Alternative Book Publishing Tools.
For more technical details about Bookdown, and examples of other publications built with this tool, see https://bookdown.org:
- Xie, Yihui. Bookdown: Authoring Books and Technical Documents with R Markdown. Chapman & Hall/CRC, 2018. https://bookdown.org/yihui/bookdown/.
- Xie, Yihui, J. J. Allaire, and Garrett Grolemund. R Markdown: The Definitive Guide. Chapman & Hall/CRC, 2020. https://bookdown.org/yihui/rmarkdown/.
- Xie, Yihui, Christophe Dervieux, and Emily Riederer. R Markdown Cookbook. Chapman & Hall/CRC, 2020. https://bookdown.org/yihui/rmarkdown-cookbook/.